MuCAN: Multi-Correspondence Aggregation Network for Video Super-Resolution¶
Video super-resolution (VSR) aims to utilize multiple low-resolution frames to generate a high-resolution prediction for each frame. The authors argues that there are two main limitations for existing VSR methods:
Flow estimation is error-prone and affects recovery results.
Similar patterns in natural images are rarely exploited.
In this work, the authors propose the multi-correspondence aggregation network (MuCAN) for VSR. This method achieves SOTA results on REDS and Vimeo-90K datasets.
In contrast to previous methods that model VSR as separate alignment and regression stages, the authors view this problem as an inter- and intra-frame correspondence aggregation task.
Inter-frame correspondence: Motion estimation may suffer from inevitable errors so the authors resort to simultaneously consider multiple correspondence candidates for each pixel. They propose a temporal multi-correspondence aggregation module (TM-CAM) for alignment.

Intra-frame correspondence: Similar pattern within each frame can benefit detail restoration. The authors design a new cross-scale nonlocal-correspondence aggregation module (CN-CAM) to exploit multi-scale self-similarity property.

Proposed Method¶
Given \(2N + 1\) consecutive low-resolution frames \(\{\mathbf{I}_{t-N}^L, \dots, \mathbf{I}_t^L, \dots, \mathbf{I}_{t+N}^L\}\), MuCAN predicts a high-resolution central image \(\mathbf{I}_t^H\). It consists of three modules: TM-CAM, CXN-CAM, and a reconstruction module.

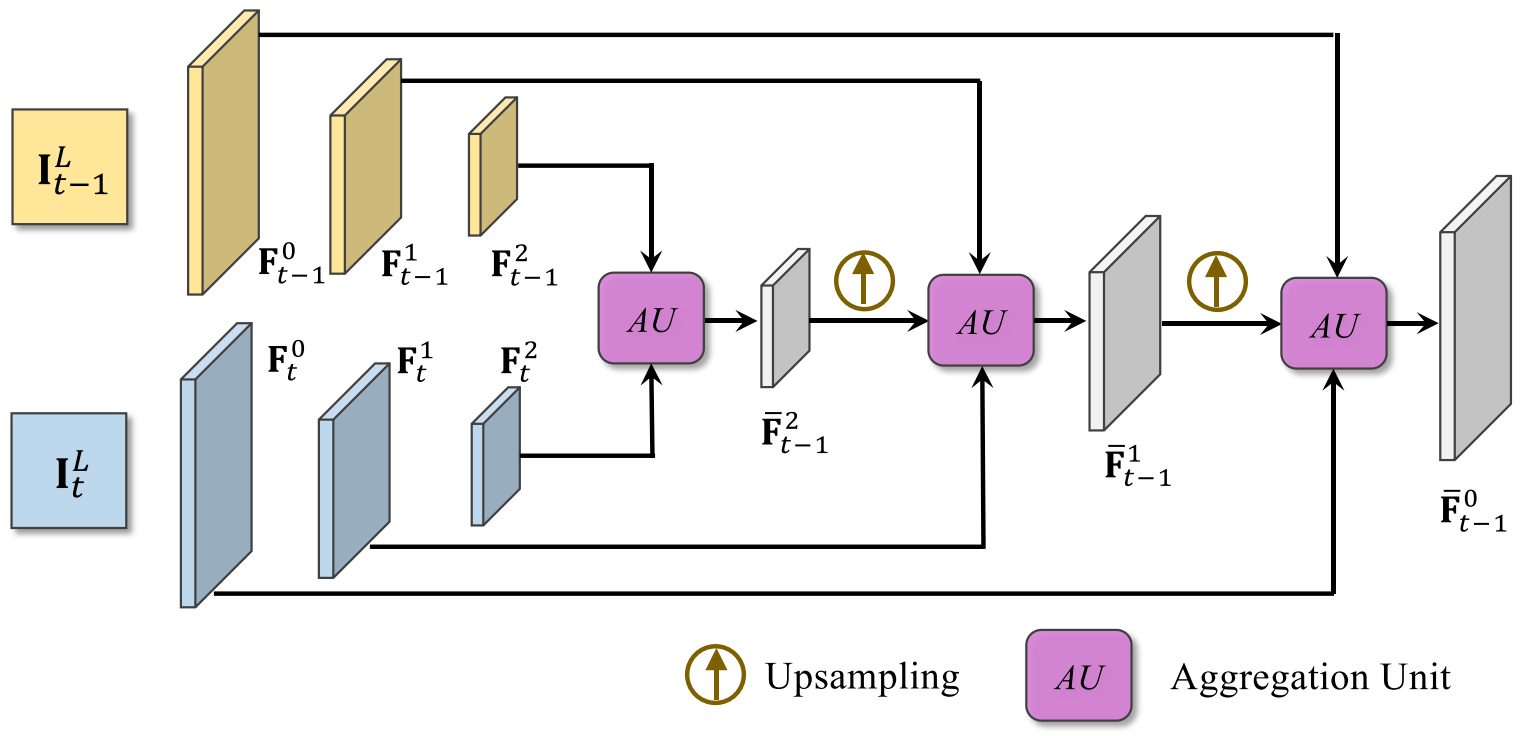
Temporal Multi-Correspondence Aggregation Module (TM-CAM)¶
The authors design a hierarchical correspondence aggregation strategy to handle large and subtle motion simultaneously.
Given two neighboring low resolution images \(\mathbf{I}_{t-1}^L\) and \(\mathbf{I}_t^L\), they first encode them into lower resolutions. Then the aggregation starts in the lower resolution stage compensating large motion, while progressively moving up to higher resolution stages for subtle sub-pixel shift.
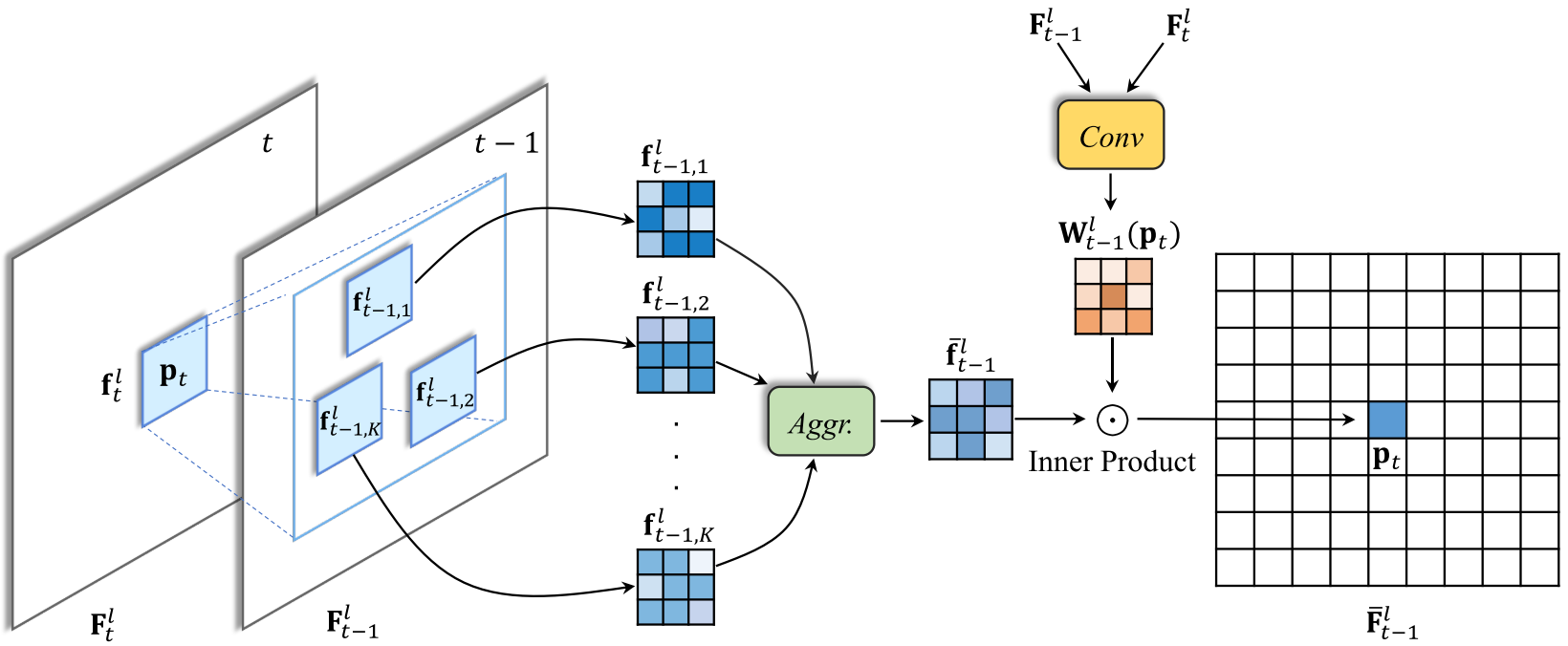
The authors use correlation as the distance measure:
By calculating correlations, we can find the top-K most correlated patches (in a local search area) in a descending order, and concatenate and aggregate them using convolution layers. In order to enable varying aggregation patterns in different locations, they further introduce a weight map obtained by concatenating the feature maps and going through a convolution layer.
Finally, the value at position \(\mathbf{p}_t\) on the aligned neighboring frame \(\bar{\mathbf{F}}_{t-1}^l\) is obtained as
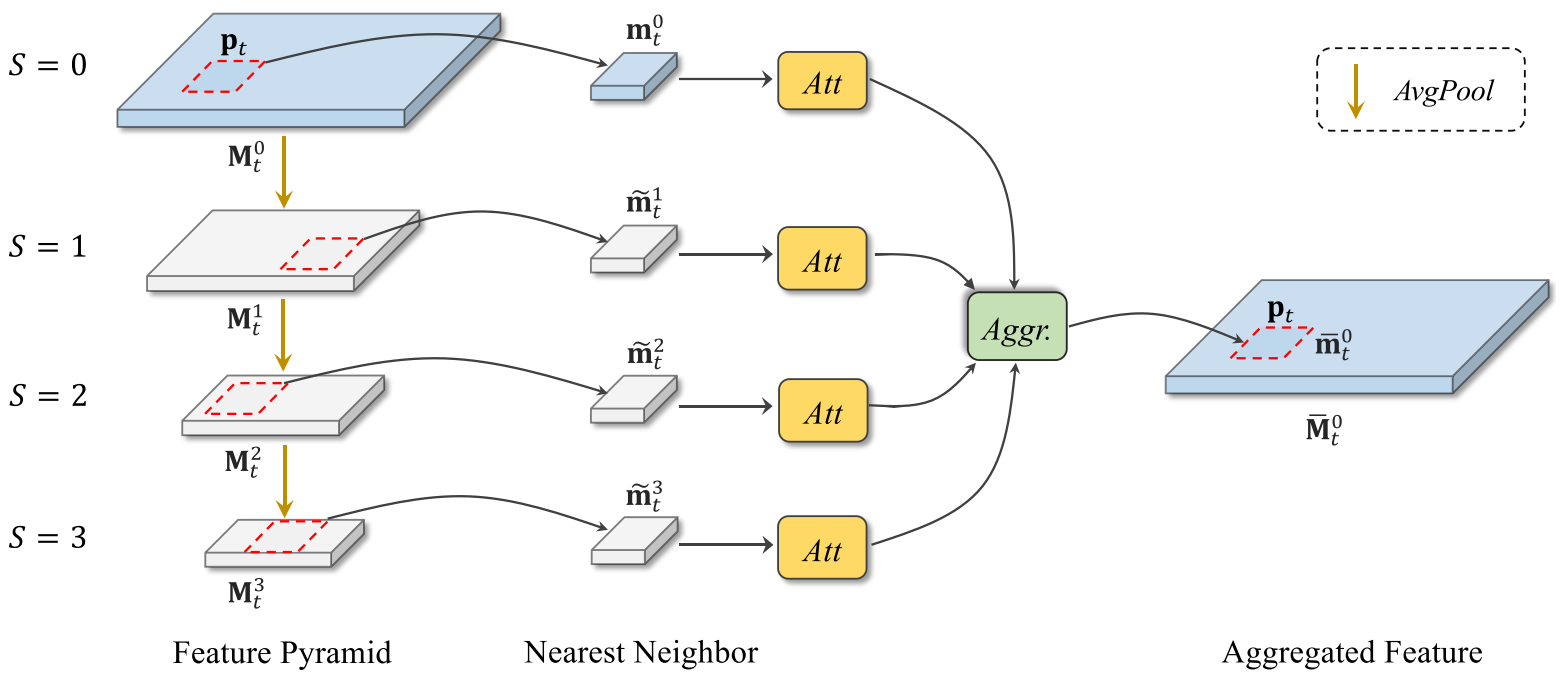
Cross-Scale Nonlocal-Correspondence Aggregation Module (CN-CAM)¶
With average pooling, the authors first downsampling the input features maps and obtain a feature pyramid. Given a query patch in \(\mathbf{M}_t^0\), the nearest neighbor patch is found in each stage. Further, a self-attention module [1] is applied to determine whether the information is useful.
Finally, the aggregated feature \(\bar{\mathbf{m}}_t^0\) at position \(\mathbf{p}_t\) is calculated as:
Edge-Aware Loss¶
Usually reconstructed high resolution images produced by VSR methods suffer from jagged edges. The authors propose an edge-aware loss to produce better refined edges. An edge detector first extract edge information from ground-truth HR images. Then the detected edge areas are weighted more in loss calculation.
During training, they adopted the Charbonnier loss, defined as:
The final loss is formulated as:
where \(\circ\) stands for element-wise multiplication.
References¶
[1] Wang, X., Chan, K. C., Yu, K., Dong, C., & Change Loy, C. (2019). Edvr: Video restoration with enhanced deformable convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 0-0).