An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)¶
Inspired by the Transformer scaling sucesses in NLP, the authors experiment with applying a standard Transformer directly to images, with the fewest possible modifications.
When trained on mid-sized datasets such as ImageNet, such models yield modest accuracies of a few percentage points below ResNets of comparable size. This outcome may be expected: Transformers lack some of inductive biases inherent to CNNs, such as translation equivalence and locality, and therefore do not generalize well when trained on insufficient amounts of data.
However, when pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks, Vision Transformer (ViT) attains excellent results compared to SOTA CNNs while requiring substantially fewer computational resources to train.
Vision Transformer (ViT)¶
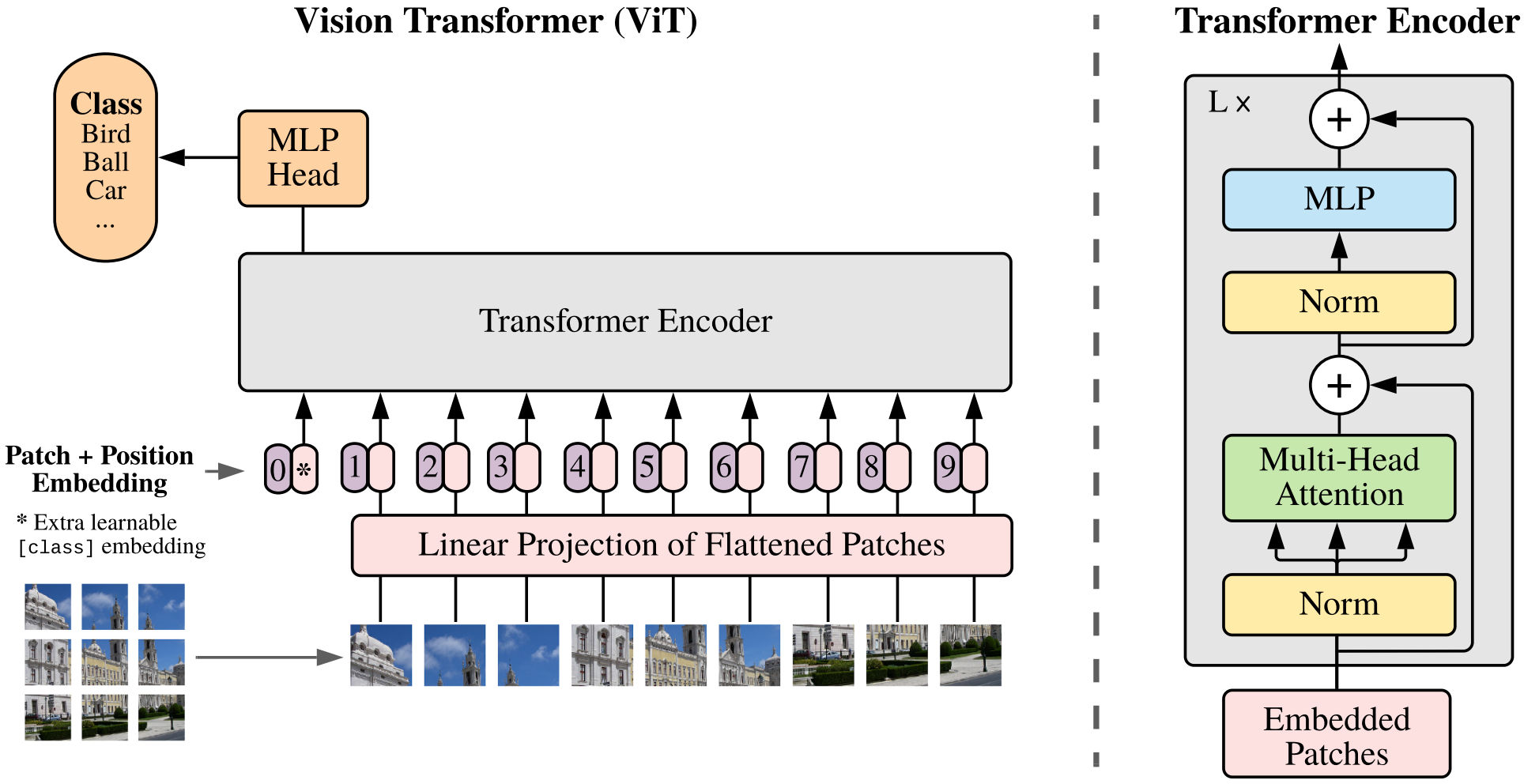
In model design, the authors follow the original Transformer [1] as closely as possible.
Patch embedding: The authors first reshape the image \(\mathbf{x} \in \mathbb{R}^{H \times W \times C}\) into a sequence of flattened 2D patches \(\mathbf{x}_p \in \mathbb{R}^{N \times (P^2 \cdot C)}\), where \(N = HW / P^2\) serves as the effective input sequence length for the Transformer. The Transformer uses constant latent vector size \(D\) through all of its layers, so they flatten the patches and map to \(D\) dimensions with a trainable linear projection.
Learnable embedding: Similar to BERT’s [class] token, the authors prepend a learnable embedding to the sequence of embedded patches (\(\mathbf{z}_0^0 = \mathbf{x}_\text{class}\)), whose state at the output of the Transformer encoder (\(\mathbf{z}_L^0\)) serves as the image representation \(\mathbf{y}\).
Position embedding: Standard learnable 1D position embeddings are added to the patch embeddings to retain positional information.
Transformer encoder: The Transformer encoder consists of alternating layers of multihead self-attention (MSA) and MLP blocks. Layernorm (LN) is applied before every block, and residual connections after every block [2, 3]. The MLP contains two layers with a GELU non-linearity.
Fine-Tuning and Higher Resolution¶
When fine-tuning to smaller downstream tasks, we remove the pre-trained prediction head and attain a zero-initiated \(D \times K\) feedforward layer, where \(K\) is the number of downstream classes.
When feeding images of higher resolution, the authors keep the patch size the same, which results in a larger effective sequence length and makes the pre-trained position embeddings meaningless. They therefore perform 2D interpolation of the pre-trained position embeddings according to their location in the original image.
Conclusion¶
While the initial results are encouraging, many challenges remain:
Apply to ViT to other CV tasks, such as detection and segmentation [4]
Continue exploring self-supervised pre-training methods
Further scaling of ViT would likely lead to improved performance
References¶
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
[2] Wang, Q., Li, B., Xiao, T., Zhu, J., Li, C., Wong, D. F., & Chao, L. S. (2019). Learning deep transformer models for machine translation. arXiv preprint arXiv:1906.01787.
[3] Baevski, A., & Auli, M. (2018). Adaptive input representations for neural language modeling. arXiv preprint arXiv:1809.10853.
[4] Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-End Object Detection with Transformers. arXiv preprint arXiv:2005.12872.