Image Based Virtual Try-On Network from Unpaired Data¶
This paper presents a new image-based virtual try-on approach (Outfit-VITON) that helps visualize how a composition of clothing items selected from various reference images form a cohesive outfit on a person in a query image. The authors provide an inexpensive data collection and training process, and introduce an online optimization capability for virtual try-on that accurately synthesizes fine garment features.

Outfit Virtual Try-On (O-VITON)¶
This system uses multiple reference images of people wearing garments varying in shape and style.
Similar to the Pix2PixHD approach, the generator \(G\) is conditioned on a semantic segmentation map and on an appearance map generated by an encoder \(E\). The autoencoder assigns to each semantic region in the segmentation map a low-dimensional feature vector representing the region appearance. These appearance-based features enable control over the appearance of the output image and address the lack of diversity.
- O-VITON consists of three main steps:
Generating a segmentation map that consistently combines the sihouttes (shape) of the selected reference garments with the segmentation map of the query image.
Generating a photo-realistic image dressed with the garments selected from the reference images.
Online optimization to refine the appearance of the final output image.
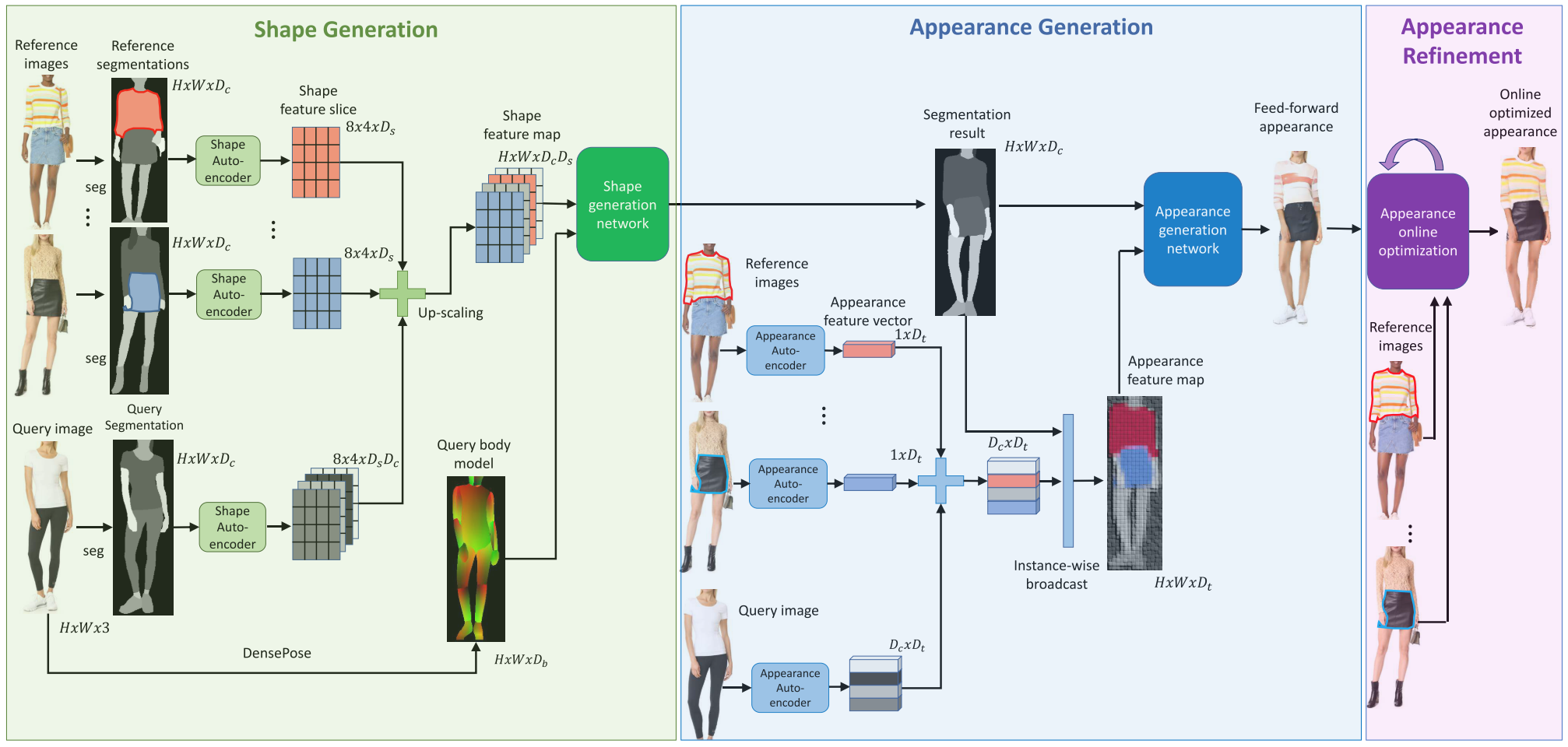
Feed-Forward Generation¶
- The inputs of the system are:
a \(H \times W\) query image \(x^0\)
a set of \(M\) \(H \times W\) reference images \((x^1, \dots, x^M)\)
A PSP semantic segmentation network \(S\) is trained which outputs \(s^m = S(x^m)\) of size \(H \times W \times D_c\). Here class \(c\) can be a body part such as face or right arm, or a garment type such as tops, pants, jacket or background. Further a DensePose network is applied to estimate a body model \(b = B(x^0)\) of size \(H \times W \times D_b\).
Shape generation: The shape-generation network combines the body model \(b\) with the shapes of the selected garments \(\{s^m\}_{m=1}^M\). A shape encoder \(E_{shape}\) followed by a local pooling step maps this mask to a shape feature slice \(e_{m, c}^8 = E_{shape}(M_{m, c})\) of \(8 \times 4 \times D_s\) dimensions. By concatenating them along the depth dimension, we get a coarse shape feature map \(\bar{e}^s\) of \(8 \times 4 \times D_s \times D_c\) dimensions, and the up-scaled version \(e^s\) of \(H \times W \times D_sD_c\) dimensions. The shape feature map \(e^s\) and the body model \(b\) are fed into the shape generator network \(G_{shape}\) to generate a new, transformed segmentation map \(s^y\) of the query person wearing the selected reference garments \(s^y = G_{shape}(b, e^s)\).
Appearance generation: An appearance autoencoder \(E_{app}(x^m, s^m)\) is applied to the RGB images and their segmentation maps \((x^m, s^m)\). The output is denoted as \(\bar{e}_m^t\) of \(H \times W \times D_t\) dimensions. By region-wise average pooling according to the mask \(M_{m, c}\) they form a \(D_t\) dimensional vector \(e_{m, c}^t\). The appearance generator \(G_{app}\) takes the segmentation map \(s^y\) and the appearance featuer map \(e^t\) as the condition and generates an output \(y\) representing the feed-forward virtual try-on output \(y = G_{app}(s^y, e^t)\).
Train Phase¶

Online Optimization¶
- There are two remaining issues:
Less frequent garments with non-repetitive patterns are more challenging due to both their irregular pattern and reduced representation.
No matter how big the training set is, it will never be sufficiently large to cover all possible garment pattern and shape variations.
Thoughts¶
Problem¶
Image-based virtual try-on that supports synthesizing a single, coherent outfit that consists of multiple garments:

Main contributions¶
A new virtual try-on framework, Outfit-VITON
An inexpensive data collection and training process that uses unpaired data
An online optimization for fine garment features like textures, logos and embroidery
Method Overview¶
Shape generation: generating a segmentation map that combines the sihouttes of the garments with the segmentation map of the query image - A PSP semantic segmentation model is used to segment the query and reference images into \(D_c\) classes which include body parts and garment types - A DensePose network is used to capture the pose and body shape of humans \(b\) - A shape autoencoder encodes the one-hot segmentation of \(H \times W \times D_c\) into \(8 \times 4 \times D_s\) dimensions - The shape generator is given by \(s^y = G_{shape}(b, e^s)\)
Appearance generation: generating a photo-realistic image showing the person in the query image dressed with the selected garments - An appearance encoder that encode appearance features into \(H \times W \times D_t\) and then pooling to \(1 \times D_t\) - The appearance generator is given by \(y = G_{app}(s^y, e^t)\)
Online optimization: refine the appearance
Train Phase¶
Idea¶
What about using the framework of a CycleGAN? Consider the case below:

Let a training pair be \(x^0 + (x^1, x^2)\) where \(x^0\) is the query image and \(x^1\), \(x^2\) are two reference images. The output of the framework would be:
We should further enforce that